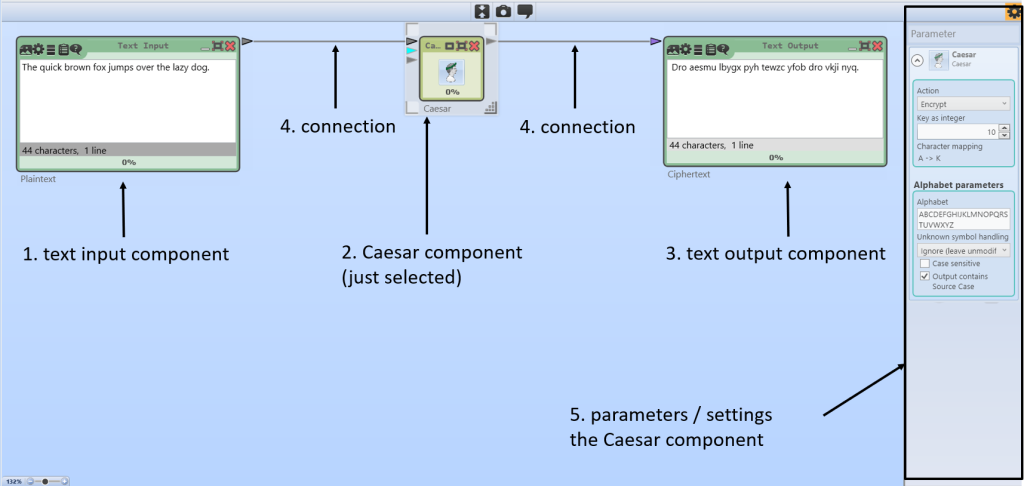
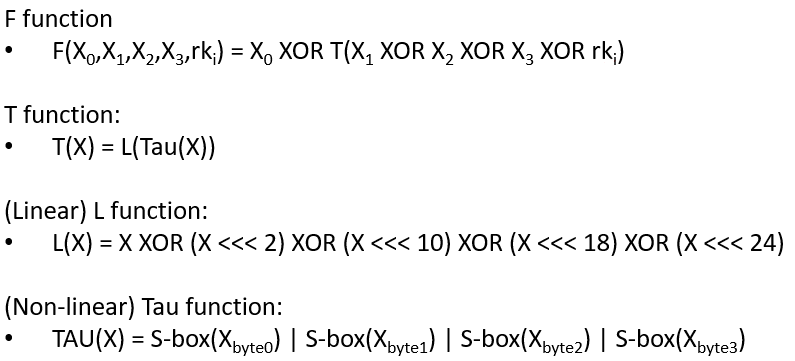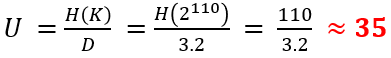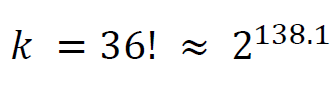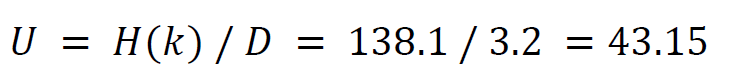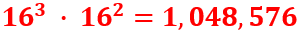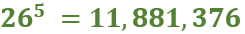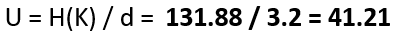In September 2025 I was invited to speak at MuseumsUNI in the Museum Schloss Rheydt in Mönchengladbach. In front of about 60 pupils I gave a talk called “Geheime Botschaften knacken – Secret Message Cracking”. I’ve now re-recorded it in English for my YouTube channel “Cryptography for everybody”, and I’d like to briefly introduce it here.
What the talk is about
We start with a simple question:
How can we read an encrypted historical letter if we don’t know the key?
To answer it, I first show some basics using classical ciphers such as the Caesar cipher and monoalphabetic substitutions. We look at why big key spaces don’t automatically mean security, and how letter frequencies and patterns still betray the underlying language.
From there I move on to the modern tools we use today. With CrypTool 2 we can:
compute letter and n-gram statistics,
run heuristic attacks like hillclimbing,
and test thousands of key candidates per second.
This is exactly the kind of software support we developed and used in the DECRYPT project and in my daily research (in the new DESCRYPT projekt :-)).
Three historical crypto stories
The heart of the talk is three short case studies:
Maximilian II’s election letters (1570s) – encrypted with a mixture of symbols, numbers and special characters; together with Michelle Waldispühl we reconstructed the system and read the emperor’s “campaign strategy”.
The Ramanacoil cipher (1674) – a VOC letter sent from Ceylon to the Netherlands, using alchemical symbols and code signs for places like Ceylon and Ramanacoil, decrypted with the help of an original key and CrypTool 2.
The UCL Brougham letter (1724) – discovered on social media, initially looked like a complex homophonic system, but turned out to be a surprisingly simple numeric substitution once we removed the nulls.
Each example shows a different mixture of paleography, language expertise and computer-based cryptanalysis. I also have detailed blog articles on this blog 🙂
Why you might enjoy the video
If you are curious about:
how historical ciphers actually worked,
how we combine archives, software and a bit of stubbornness,
and how “mysterious symbols” slowly turn into readable text,
then this talk might be fun for you. It’s aimed at interested students, developers and anyone who likes a mix of history, cryptography and a bit of detective work.
After a longer break, I’m excited to finally share the first episode in my new video series Applied Cryptography. This project is based directly on the university lecture I teach at Cyber Campus NRW, part of Hochschule Niederrhein. The series is designed for anyone—students, developers, or security enthusiasts—who wants to truly understand the science behind secure communication.
What is Cryptology, Really?
Many people use the terms cryptography and cryptology interchangeably, but cryptography is only one side of the story. The other half is cryptanalysis—the art of breaking cryptographic systems. In this first episode, we define these core terms and explore their historical development. Drawing on the work of William F. Friedman, often considered the father of modern cryptology, we clarify the differences and explain how these disciplines have changed with the advent of computers—and how quantum computing might transform them again.
From Caesar to Cyber: A Journey Through Cryptographic History
This course places also a strong emphasis on history. In the first video, we revisit important milestones in cryptography—from ancient tools like the Spartan Scytale and Caesar’s cipher, through the breaking of the Enigma during World War II, to modern controversies such as NSA backdoors and the Snowden revelations. These examples show that cryptology is not just theoretical—it has changed the course of history.
Key Concepts: Ciphers, Key Exchange, and the Limits of Security
We also dive into key technical concepts, including:
Kerckhoff’s Principle – why strong encryption should not depend on secrecy
The Key Exchange Problem – how to share keys securely over insecure channels
Types of Cryptanalytic Attacks – including brute-force, chosen-plaintext, and ciphertext-only attacks
Plus, we introduce the famous characters Alice, Bob, Eve, and Mallory—used to illustrate communication scenarios and attacks.
Tools for Hands-On Learning
To make cryptographic concepts more accessible, I demonstrate CrypTool 2, our free, open-source tool for exploring cryptographic algorithms and attacks. Whether you want to simulate classical ciphers or analyze modern encryption methods, CrypTool 2 provides an interactive environment for experimentation.
Within the collections of the Riksarkivet (the Swedish National Archives) lies a four pages long letter that probably had remained undeciphered for centuries. It was written in 1637 by nobleman Sigismund Heusner von Wandersleben to the Swedish High Lord Chancellor Axel Oxenstierna. Heusner encrypted parts of the letter with a complex cipher and it presented a challenge, which my colleague Michelle Waldispühl and I tackled. The letter was first brought to our attention by our DECRYPT project leader, Beáta Megyesi, who discovered it during her research in the archives and shared it with us. This blog post discusses our systematic approach to cryptanalyze this historical document and the insights we gained from it.
Axel Oxenstierna af Södermöre, 1583-1654. Image taken from Wikipedia
The Discovery of the Letter
The letter was part of the “Oxenstierna samlingen”, a collection of correspondence preserved in the Riksarkivet (the Swedish National Archives). This particular letter, part of a series written by Heusner von Wandersleben between 1632 and 1638, was the only one encrypted, maybe hinting at the importance of its contents. The DECRYPT project leader Beáta Megyesi found the letter and knew that Michelle and me already successfully worked on German historical encrypted letters. Thus, she brought it to our attention, and we began our collaborative effort to decipher it, which resulted in a mutual research paper (see [1]) as well as a poster, which we, Michelle and me, presented together on the HistoCrypt 2024 in Oxford. The letter, of course, has its own entry in the DECODE database, which you can find here [2]. In the following image, you can see the first page of the partially encrypted letter from 1637.
First page of the partially encrypted letter sent from From German Nobleman Sigismund Heusner von Wandersleben to Swedish Chancellor Axel Oxenstierna during the Thirty Years’ War. The letter is located in the Riksarkivet (the Swedish National Archives).
The Cryptanalysis Process
Our first task was to understand the nature of the encryption. The letter’s ciphertext consisted of numbers separated by dots, indicating the use of a homophonic substitution cipher. This cipher type is particularly challenging because it employs multiple so-called homophones to represent single letters, thereby obscuring the original letter frequency as well as patterns that are typically exploited in cryptanalysis of hand ciphers.
To begin the actual cryptanalysis, we transcribed the entire letter with the help of Transkribus.ai, a tool designed for the recognition of historical handwriting. Given the challenges posed by the 17th-century German script, which was written in “Deutsche Kurrent Schrift” (German Kurrent writing), this step required meticulous attention to detail, since the results of the machine-based transcription were good but far from perfect. Every digit and symbol was carefully validated to ensure accuracy in the transcription. We checked of the ciphertext symbols (the numbers) manually and had to correct many of them.
With a complete and accurate transcription in hand, we used to CrypTool 2 (CT2), our open-source cryptanalysis software, that we have frequently employed in our prior work. The Homophonic Substitution Analyzer of CT2 was our primary tool, allowing us to perform semi-automated cryptanalysis of the letter. Through multiple iterations of cryptanalysis and refinement of the assignments of plaintext to ciphertext symbols, we gradually began to uncover portions of the plaintext. During the cryptanalysis, we identified 85 distinct homophones used in the ciphertext. These homophones were not evenly distributed—some letters, such as ‘e’, were represented by as many as eight different numbers, while others had only one. This uneven distribution suggested a deliberate attempt by the cipher creator to complicate decryption efforts. Additionally, the absence of word separators and punctuation in the ciphertext parts added to the complexity, making it difficult to determine sentence boundaries and syntactic structures.
Nomenclatures and the Limits of Decipherment
A particularly aspect of the letter was the presence of nomenclature elements—three-digit codes embedded within the ciphertext. These elements likely represented names of individuals or places, critical pieces of information that the sender wanted to protect with additional security. Despite our best efforts, these nomenclature elements remained undeciphered. The only possibility to decipher these is either to find the original key or guess their meaning with the help context. We searched in the DECODE database as well as in the “Hessisches Staatsarchiv” (Hesse State Archive), which holds many original German keys from the Thirty Years’ War, but we were not able to find the original key.
The use of nomenclature elements is consistent with the regular practices of the time, particularly in diplomatic and military communications. Nomenclature elements and their corresponding tables ultimately lead to the invention of code books, which were mainly in use in the 19th and early 20th century.
The Deciphered Letter and a ChatGPT Translation
Here is the unedited transcribed and deciphered German version of the original letter. An English translation generated with ChatGPT is below. The German text still contains errors as well as the undeciphered nomenclature elements (numbers). Also, the originally encrypted parts are all written uppercase:
1637, Mai 15 Hochwohlgeborner Herr Reichchanzlar undt Director gnediger Herr, Eurer Excell. habe vom 20. Xmbr. des 36. und 3. Febr. dieses 37. ihars ich vnderthenig zuerkennen gegeben, wie ich vnuerrichtetdeter dinge mit Herrn Feldmarschalch Johan Banners Ex. in wiederwillen gerathen, darbei vmb schutzs und remedirung gehorsambst gebeten, darauf mich zu Herrn Feldmarschalch Leßels arm´ee vf seine bitte gewendet. Als aber jüngsthin die Coniunction in Meißen wiederumb vorgangen, sond ich von gueten freunden gewarnet worden, mich nicht allein vor Herrn Feldmarschalch Bännnern, sondern auch anderen, und sonderlichen Hern Frantz Heinrichen zu Sachsßen, wegen der Hamburger Sache vorzusehen, da sie mier leute vff den hals schicken wolten, hab ich mich vff 164. retiriret, alda ich noch verbleibe. Wiewohl ich nun vermeinet, dessen orts DIE ALTE DEUOTION GEGEN DIE CRON ZU FINDEN. So erfahre ich aber das HERR UND KNECHT SEHR GEENDERT UND AM GANZEN HOFE AUSSER DER 503. NICHTT EINER MEHR UFFRECHT SCHWEDISCH, IA DER 628. FAUORISIREI und CARESRIRET aizo die so in SEINEM ABWESEN dem 503. ZUWIEDER GEWESEN und die 764. UBERGEBEN wollen, daher ich mich nicht wenig Verwundert wie L.EWOLFF DERORTEN NEGOCIIREN SONNEN, deme es furwahr an nottieftigen vnderhalt, in? sogar das ich darfur erschrocken, h¨ochlichen gebracht?, UON EINEM FELDZUG wirdt geredet, WOHIN IST STILL. Es kan aber nichts großes sein, dan die FORCE nicht alda, und man der Zeit nicht BASTANT 808. 385. 184. AUS DEM LANDT ZU TREIBEN da 503. SOLL IN DAS FELD und ein anderer AUS DEM LANDT in 321. damit ist es ein KUCHEN Vff die 255. BESTALLUNG ingleichen die 289. GELDER machet man GROSSES HERANTZ und viehl REDENS UON. Es ist aber das erste NOCG NICHT CLAR und kan was E. Ex. die sache mit SELBER CRON dero hohen verstandt nach 747. und den 617. RECHT IM DIRECTORIO FASSEN schon alles dergestalt gemacht werden, das man DOCH DIE CRON 708. SUCHEN und von derselben DEPENDIREN UND BITTEN muss von deren MAN SICH SONSTEN AUSZUHALFETERN GEMEINET. Wegen des andern ist kein vberflues, und erfolget sparsam genug, das sich also die sachen wohl geben, Euer Ex. habe meiner schuldigkeit nach ich dieses mit wenigen gehorsamlichen anfuegen wollen, die ich des allerh¨ochsten schvzs? und dero zu beharrlich gnaden mich vnderthenig empfehle und dero resolution mit sachßen erwarte, Vol. CASSEL den 15. May 1637. Eurer Excelz. Werthiger gehorsamer diener 384. ich habe mich des EWOLFREN seines Comptorii? et? Man hat hier in der aller größen geheimb etlich 385. CENTNER METALLISCHE SPEISSE ZUSAMMEN GESCHMELZET und solche verdecket auf 147 gef¨uret, daselbst etliche schon hierzu gemachte STUCKE ZU TAUSCHEN und werden mit dem UFFBRUCH wie ich in vertrauen vernommen den nechsten sich eihlen undt ALLE ABWERTS GEHEN. Alhier wie ich Vermercke wirdt IOHAN VON UFFELN COMMENDANT 571. GUNTEROT aber GEHET MIT ANDEREN ZU FELDT varleßet sich mercken, ob seye etwas UON 703. ALHIER wie auch ANDERE und haben GROSSE HOFFNUNG. Dieses wird gleich bey schließung meines schreibens ahn? EWOLFFEN bey einem gueten ort geschrieben.
And here, I used ChatGPT to translate the letter in the following. Keep in mind that the translated text is an AI-generated translation, where I asked ChatGPT to keep the uppercase written words to show the originally encrypted parts. Clearly, the translation can contain (more) errors introduced by the AI:
1637, May 15 Noble Lord Chancellor and Director, gracious Sir, Your Excellency, on December 20 of the year 1636 and on February 3 of this year 1637, I humbly informed you of how I, due to unresolved matters, fell into conflict with His Excellency Field Marshal Johan Banner and respectfully requested protection and remedy. Consequently, I turned to the army of Field Marshal Leßel at his request. However, when the conjunction in Meißen recently occurred again, I was warned by good friends not only to be cautious of Field Marshal Banner but also of others, particularly Lord Franz Heinrich of Saxony, concerning the Hamburg matter, as they intended to send men after me. I have therefore retreated to 164., where I still remain. Although I expected to find THE OLD DEVOTION TO THE CROWN in this place, I have discovered that MASTER AND SERVANT HAVE CHANGED GREATLY and at the entire court, except for the 503., THERE IS NOT ONE WHO REMAINS LOYAL TO SWEDEN; INDEED, THE 628. IS FAVORED AND FLATTERED, meaning those who, in HIS ABSENCE, stood AGAINST the 503. and want to hand over the 764. Therefore, I am quite astonished how L. EWOLFF can negotiate there, as he truly lacks the most essential resources, so much so that I am greatly alarmed. There is talk of a military campaign, WHERE TO IS UNCLEAR. However, it cannot be anything significant, as the forces are not present there, and at present, one is not SUFFICIENTLY 808. 385. 184. TO DRIVE OUT OF THE LAND. The 503. SHALL GO INTO THE FIELD and another OUT OF THE LAND to 321., which makes it a game. On the 255. APPOINTMENT as well as the 289. FUNDS, great attention is being paid and much talk is made. However, the first matter is NOT YET CLEAR and what Your Excellency can make of the situation with THE SAME CROWN according to your high understanding of the 747. and the 617. LAW IN THE DIRECTORY, everything could already be arranged in such a way that one MUST STILL SEEK THE CROWN 708. and DEPEND AND REQUEST from it, from which one otherwise intended to distance oneself. As for the other matter, there is no excess, and it follows sparingly enough that things may well turn out as expected. Your Excellency, I have dutifully wanted to add a few obedient words, in which I humbly recommend myself to the highest protection and your continuous grace, and await your decision with Saxony. Vol. CASSEL, May 15, 1637. Your Excellency’s most worthy obedient servant, 384. I have used the EWOLFFREN’s office? et? Here, in the greatest secrecy, about 385. CENTNER OF METALLIC FODDER HAS BEEN MELTED TOGETHER and covertly transported to 147., where several pieces already made for this purpose are to be exchanged, and with the DEPARTURE, as I have learned in confidence, they will hasten in the next few days, and ALL WILL GO DOWNWARD. Here, as I note, IOHAN VON UFFELN will become COMMANDANT 571., but GUNTEROT WILL GO TO THE FIELD with others. It remains to be seen whether anything of 703. will occur here, as well as with OTHERS, and they have GREAT HOPE. This will be written to EWOLFFEN at a good place immediately upon the closing of my letter.
On the last page of the letter, the name of the German city Kassel is also encrypted. This indicates, that the letter was probably sent from or at least written in Kassel.
What the Letter Revealed in a Nutshell
Despite the challenging cryptanalysis and open problems with the nomenclature elements, we were able to decipher significant portions of the letter. The revealed plaintext provided insights into the political and military concerns of the era. Sigismund Heusner von Wandersleben, who served as a Swedish counselor and war commissioner, wrote to Axel Oxenstierna about ongoing conflicts with other military leaders, including Johan Banér and Franz Heinrich of Saxony.
The letter detailed strategic retreats and expressed concerns about potential threats from various factions involved in the Thirty Years’ War. Heusner von Wandersleben sought guidance from Oxenstierna, reflecting the high stakes and pressures faced by those managing the war effort. The letter also addressed financial matters and the deployment of military forces.
Interestingly, the used encryption did not hide all secrets, which were shown within the text. Many information, that seem really important to us, were not encrypted by Heusner while some parts, which contained non-confidential information, were encrypted.
Challenges and Insights Gained
The process of cryptanalyzing and deciphering this letter was both challenging and rewarding. The high number of homophones and the uneven distribution of symbols added a very significant level of difficulty to our cryptanalysis. The absence of an original cipher key meant that we had to rely entirely on CrypTool 2 and the Homophonic Substitution Analyzer to uncover the plaintext. Also, since Michelle is a great expert of old German dialects, her work on the language of the letter and help with the deciphering was crucial. Without her, I would not have been able to decipher and understand the letter to the degree which we were able as a team. So as good as your cryptanalytical tools and efforts may be, there is nothing that can replace a language expert helping you :-).
Our Conclusion
Our combined work on deciphering this 1637 letter has provided interesting insights into the cryptographic practices during the Thirty Years’ War, especially in the German-Swedish relation between Oxenstierna and Wandersleben. The partial decipherment of the letter showed parts of their political and military strategies, while the unresolved nomenclature elements still keep many of their secrets, which we were not able to reveal. Also, this project again shows the importance of interdisciplinary collaboration in historical cryptography, combining the linguistic expertise with modern cryptanalytic methods and algorithms.
As I continue my research, I look forward to further exploring the complexities of historical ciphers like this one. Finally, the journey to fully decipher this letter is far from over, since the nomenclature elements are still not deciphered. We hope to find the original key, thus, we are also able to reveal their meanings.
References
[1] Waldispühl, Michelle & Kopal, Nils. (2024). Decipherment of a German encrypted letter sent from Sigismund Heusner von Wandersleben to Axel Oxenstierna in 1637. 10.58009/aere-perennius0116. [2] DECODE Record 4332: The letter and our analysis results in the DECODE database. URL: https://de-crypt.org/decrypt-web/RecordsView/4332
In a routine cataloging task at the University College London (UCL) Special Collections, an interesting and mystical 1724 encrypted letter came to light, which captured my attention. As someone deeply involved in the field of historical cryptography, I was drawn into the process of decrypting this document. This blog article details my journey in decrypting the letter, the methods I employed, the historical context, and the insights we gained.
Portrait of Jeanne-Agnès Berthelot de Pléneufs after Jean-Baptiste van Loo, 18th century (source Wikipedia)
Discovery of the Letter and Contact to the Archive
Katy Makin, an archivist at UCL, discovered the encrypted letter while cataloging the Brougham Archives. These archives are primarily associated with Henry Brougham, 1st Baron Brougham and Vaux, a notable British statesman of the 19th century. However, the letter predates Brougham’s birth by over 50 years, indicating it might be linked to one of his ancestors involved in the political affairs of the early 18th century.
Katy decided to share images of the letter on social media, specifically on X (formerly known as Twitter), in hopes of finding someone able to decipher it. I came across these images on X, and given my background in decrypting historical documents, I was immediately captivated by the challenge.
After I was able to decipher the first pages shown on X, I immediateley realized that there have to be more. I contacted Katy, showed her my decryption and also asked for more pages. She sent all pages to me which I also was able to decipher. Unfortunately, it also turned out that some pages are missing since the letter has no proper ending and indicates that. Ultimatively, Katy and I wrote a research article about the letter and published it on the HistoCrypt 2024 in Oxford. I also presented the letter in the poster session on the HistoCrypt which I really enjoyed.
First Page of the Encrypted Letter
Initial Analysis and Hypotheses
When I first examined the letter, it appeared to be encrypted using a homophonic substitution cipher—a method designed to obscure letter frequencies by using multiple symbols for individual letters. The letter consisted of 16 pages filled with numbers, dots, and dashes, with a few plaintext words like “and” and “the” and names such as “Mons Garnet and Gee” standing out. This mixture of encryption and plaintext hinted at a complex approach that piqued my curiosity.
Given the structure and content, I initially hypothesized that the letter might use a homophonic substitution cipher, where different numbers or symbols corresponded to letters or groups of letters. This assumption seemed plausible, especially with 52 different numbers appearing throughout the text, which might represent the plaintext alphabet and additional syllables or words.
The Decryption Process
To begin the decryption, I first transcribed the entire text into a digital format, recording every number, dot, and dash to ensure I had an accurate replica of the original document. This transcription allowed for a detailed analysis using CrypTool 2, our open-source software that I frequently use for analyzing and breaking classical ciphers, e.g. in videos on my YouTube channel.
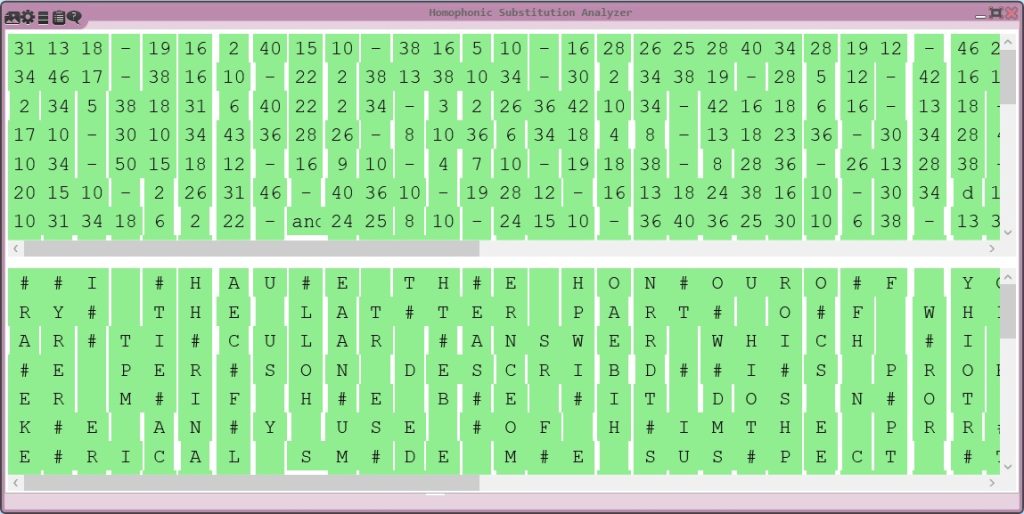
My initial attempts at automated decryption using the Homophonic Substitution Analyzer provided some partial results, but there were still many nonsensical sequences, which led me to suspect the presence of nulls. These symbols are often used to mislead those attempting to decrypt the text, adding an extra layer of difficulty.
Through further cryptanalysis, I discovered that the encryption was simpler than I had initially thought. After identifying and removing the nulls, I realized that the letter used a basic monoalphabetic substitution cipher, where even numbers corresponded to letters in a straightforward ascending order (e.g., A = 2, B = 4, C = 6, etc.). With this finding, I was able to successfully decrypt the main content of the letter.
Letter and its Decryption in CrypTool 2’s Homophonic Substitution Analyzer
Unresolved Elements and Historical Context
Despite the successful decryption of most of the text, certain elements remained unresolved. The letter contained “nomenclature elements”— special codewords likely used to hide e.g. the identities of people and places. These codewords, such as “Mons Garnet and Gee” or “Mons Grandy and Gay,” appeared in pairs and often featured alliteration. Their exact meaning remains unclear, suggesting these elements were intended to provide additional security, perhaps related to sensitive political or military issues.
The letter was written during a time of significant political tension in Britain, particularly concerning the Jacobite efforts to restore the Stuart dynasty to the throne. The use of encryption shows the sensitive nature of the topics discussed, reflecting the secretive communications common during this turbulent period.
Content of the letter
Here is the decryption of the first two pages of the letter:
Page 1: Feb 24 1724I HAUE THE HONOUR OF YOUR LETTER OF THE ?? OF IANUARY THE LATTER PART OF WHICH I THOUGHTREQUIRED A PARTICULAR ANSWER WHICH I SENDENCLOS BY ITSELF. THE PERSON DESCRIBD ISPROBABLY THE PERSON ENQUIRD AFTER AND IF HEBE IT DOS NOT SEEM TO ME THAT YOU CAN MAKEANY USE OF HIM. THE PROIECT HE PROPOSD TO MECHIMERICAL and MADE ME SUSPECT THAT
Page 2: HE WAS a MAN OF LITTLE CAPACITY OR ONE SENTBY THE COURT FROM HENCE TO TRY TO INSINUATEHIMSELF INTO YOUR GOOD OPINION IN ORDER TOBETRAY ANY CIUNSELLS OR DESIGNS OF YOURS THATMIGHT COME TO HIS KNOWLEDGE YOU HAUE. NOBATHE BEST INFORMATION JCOUD GET ABOUT HIM and whatever HE MAY BE I DONT QUESTION BUT YOUWILL THINK IT PROPER TO BE upon YOUR GUARDAGAINST HIA OR ANY OTHER PERSON THAT SHALLCOST YOU IN SUCH A MANNER. Mons Ray & Rook HAS NOW MET …
The Role of Madame de Prie in the 1724 Encrypted Letter
One of the most interesting parts of the decrypted 1724 letter is the mention of Madame de Prie, a prominent figure in French political circles during the early 18th century. Madame de Prie, the mistress of the Duke of Bourbon (“Monsieur Le Duc”), wielded significant influence at the French court, since she was basically in full control of the duke. The letter hints at her potential involvement in a secretive political scheme, suggesting that her support should be secured — through financial incentives. Interestingly, she was the only person not mentioned using a code name, which we identified so far.
Conclusion
Deciphering this 1724 letter was a really fascinating project, giving me insights into the methods of communication and encryption used in the early 18th century in England. But also, it kept me wondering why such important political communication was not secured with a more secure cipher than just a simple monoalphabetic substitution. Finally, the unresolved nomenclature elements left open the possibility of further research to identify the mentioned persons and places. This is now up to the historians :-).
References
Kopal, Nils und Makin, Katy. „Decipherment of an Encrypted Letter from 1724 Found in UCL Special Collections’ Brougham Archive”. In Proceedings of the 7th International Conference on Historical Cryptology (HistoCrypt 2024), Oxford/Bletchley Park, UK, 2024: URL: https://doi.org/10.58009/aere-perennius0104
In my journey through the world of cryptography, I’ve previously explored and shared insights on the Advanced Encryption Standard (AES) and the Data Encryption Standard (DES) — ciphers that hold a prominent place in Western cryptographic practices. Venturing further, I delved into the realm of Soviet/Russian cryptography with a detailed examination of the GOST Magma cipher in a YouTube video. Continuing on this path, I’ve now expanded my exploration to include the Chinese block cipher ShāngMì 4 (SM4 ,商密4). In the latest video on my YouTube channel (which you’ll find at the conclusion of this blog post), I explain the structure and mechanics of SM4, showcasing its unbalanced Feistel network design and its building blocks.
A look at SM4’s history
Originally named SMS4, the SM4 Block Cipher is not just an algorithm; it’s a testament to China’s stride towards self-reliance in information security. Drafted by the Data Assurance & Communication Security Center alongside the Commercial Cryptography Testing Center under the National Cryptography Administration, SM4 was officially released on March 21st, 2012. It transitioned from an internal specification to a national standard in China in August 2016. It is mainly developed by Lü Shuwang (Chinese: 吕述望).
SM4 overview
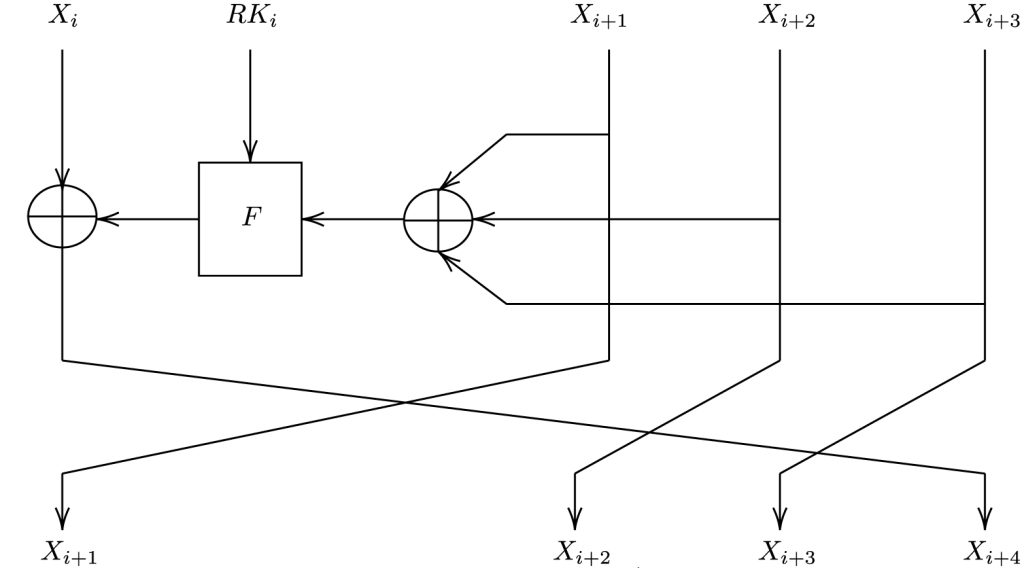
At its core, SM4 is a symmetric block cipher, characterized by a 128-bit block and key size, operating over 32 rounds. It employs an unbalanced Feistel network structure, utilizing an S-box for its non-linear transformation. Each round of the cipher involves linear and non-linear operations, including XORs, shifts, and table lookups within a so-called F function. Each round, a different of the 32 round keys is used.
SM4 single round (image from Wikipedia)
SM4 divides its 128-bit input into four 4-byte blocks (X0, X1, X2, and X3). The first block is XOR-ed with the result of the F function and becomes the new 4th block. The old second, third, and fourth blog become the new first, second, and third block.
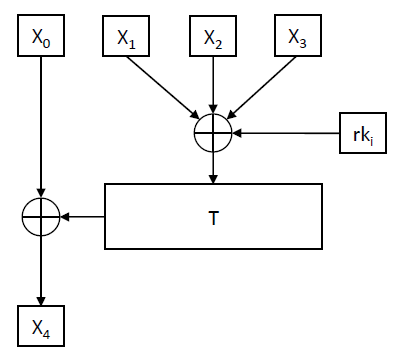
The round function is the heart of SM4: the F function
The round function of SM4, denoted as F, is where the “magic happens”. It takes in four inputs along with a round key and undergoes a series of transformations, including XOR operations and the application of the T function. The T function itself is a blend of non-linear (Tau) and linear (L) transformations, ensuring that the output is highly unpredictable, thereby enhancing security.
SM4 F function
The f Function calls the T function, which calls the L function, which calls the Tau function (S-Box lookups):
Equations of the F function (including T function, L function, and Tau function)
Below, we explain the non-linear function Tau as well as the linear function L.
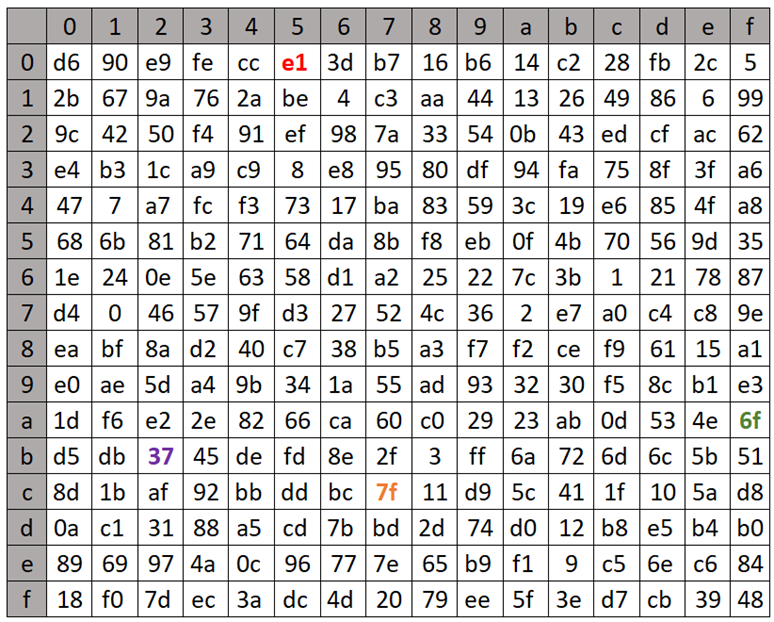
The non-linear part: the Tau function
The non-linear function Tau, a fundamental component of the SM4 block cipher, plays a crucial role in the cipher’s security by introducing complexity and thwarting linear and differential cryptanalysis attacks. This function operates on the principle of substitution, where each byte of input is replaced with a corresponding byte from a pre-defined 8-bit S-box:
SM4 S-box (lookup table with 256 entries)
The Tau function processes input data in four bytes, applying the S-box transformation to each byte independently. The S-box, which stands for substitution box, is designed to be non-linear; it maps each 8-bit input to a new 8-bit output in a way that is deliberately non-linear and hard to predict. This unpredictability is what gives the Tau function its strength against cryptographic attacks, making the cipher more secure.
For example, given a 4-byte input, the Tau function applies the S-box transformation to each of these bytes. Example (values retrieved from the lookup table are highlighted in the same colors as used in the table depicted above; shown values are in hexadecimal format):
SM4 Tau function example computation
The linear part: the L function
The L function is a the second component of the F function, serving as the linear transformation stage that follows the non-linear Tau function in the encryption algorithm. Its primary role is to disperse the output of the Tau function across the block, enhancing the diffusion of the cipher. This process is essential for ensuring that changes in a single bit of the plaintext or the key propagate widely throughout the ciphertext, a property that strengthens the cipher against various forms of cryptanalysis.
The L function operates by performing exclusive OR (XOR) operations on the input with shifted versions of itself. Specifically, it takes a 32-bit input and applies XOR with the input shifted left by 2, 10, 18, and 24 bits. This series of shifts and XORs ensures that the influence of each bit spreads across the entire block, contributing to the diffusion of the cipher. Its defined in the following equation; below is an example computation of the L function:
L function and example computation
Decryption procedure
In the Feistel cipher design, the decryption process closely mirrors encryption, with a crucial difference: the round keys are applied in the opposite sequence. This means that during decryption, the keys are used in reverse order from how they were applied in encryption. This reversal is a key feature of the used Feistel structure, enabling the algorithm to easily reverse the encryption steps and recover the original plaintext.
The key expansion
The key expansion process in the SM4 block cipher is a systematic procedure designed to generate a series of round keys from the initial master key MK. The primary objective of the key expansion is to produce 32 round keys that are both unpredictable and resistant to cryptanalytic attacks.
At the beginning of the key expansion, the algorithm takes the master key MK, which is 128 bits in length, and processes it through a combination of XOR operations, non-linear transformations, and cyclic shifts to generate 32 round keys. The master key is initially divided into four words, and these words are then combined with predefined constants known as FK to produce the initial key state.
Following the initialization, the key expansion employs a loop that iterates 32 times to generate the 32 round keys. Each iteration of the loop applies a transformation function, denoted as T’, on a combination of the current key state and another set of constants called CK . The transformation function T’ is similar to the round function T but is adapted for the key expansion process. It includes the same S-box transformation (Tau) for non-linearity and a modified linear transformation (L’) that uses different cyclic shifts:
Key expansion (equations)
A paper about the cipher
A good paper on the cipher, written (and translated? from Chinese) by Whitfield Diffie and George Ledin, offering a comprehensive explanation, is available at the following link: https://eprint.iacr.org/2008/329
This paper also includes some of the design choices and explains how the S-box was created.
My YouTube video about the cipher
Of course, I also made a YouTube video for my “Cryptography for everbody” YouTube channel :-). You can watch it here:
In the annals of history, the Dutch East India Company (VOC) stands as a monumental force in global trade and colonial expansion. Even though they were the largest trading company of their time, the cryptography they used was almost non-existent.
Secretary Leewenson and a soldier in the desert (AI-generated)
Nevertheless, there is a testimony of at least one encrypted message that even traveled 10,000 km. I, together with the Dutch Historian Jörgen Dinnissen, decrypted the letter, which can be still found in the National Archives of the Netherlands in The Hague. This blog post looks at this captivating piece of this hidden history: an encrypted letter from the VOC era. It gives an insight into the secret communications of the VOC in the 17th century.
The Dutch East India Company (VOC)
Depiction of a Dutch Fleet (AI-generated)
The United East India Company, known in Dutch as Verenigde Oost Indische Compagnie (VOC), existed from March 20, 1602, to December 31, 1799. As the largest private company of its era, the VOC’s scale and influence were comparable to modern giants like Walmart, Amazon, or Apple. At its peak, the company boasted over 150 ships, 200-250 locations across Asia, and about 20,000 employees. It held a monopoly on Asian trade, particularly in spices like nutmeg, mace, and cloves. The VOC wielded immense power, capable of waging war, negotiating treaties, and establishing colonies. The “Lords Seventeen” (Heeren XVII) were the governing body of this monumental trading empire.
The seal of the VOC
Rijckloff Van Goens
Rijckloff Van Goens, born in 1619 and passing in 1682, was a pivotal figure in the Dutch East India Company (VOC). He notably served as the Governor of Ceylon (now Sri Lanka) twice between 1662 and 1672. Renowned for his diplomacy, Van Goens rose to prominence in Batavia (now Jakarta) by age 37.
Rijcklof Van Goens 1656 1657; Source: Wikipedia
In 1655, his strategic plans for Asia were approved by the “Lords Seventeen” (leading board of the VOC) in Amsterdam, leading to successful conquests in Northwestern India, Ceylon, and Southern India by 1658. His 1663 conquest of Cochin in India secured a vital region for pepper trade. By 1674, the VOC, under his leadership, controlled Ceylon’s coast while the inland was governed by the King of Kandy.
Dutch Ceylon and the Island Ramanacoil
Dutch Ceylon, established in present-day Sri Lanka by the VOC from 1640 until 1796, was a key governorate of the Dutch colonial empire. The Dutch captured most coastal areas but were unable to control the Kingdom of Kandy in the island’s interior. Initially, the Dutch were invited by the Sinhalese king to assist in fighting the Portuguese, which led to their capture of maritime provinces and establishment of control. Galle served as the capital of Dutch Ceylon initially, shifting to Colombo in 1658. Dutch rule in Ceylon concluded in 1796 following the British takeover, influenced by geopolitical shifts in Europe.
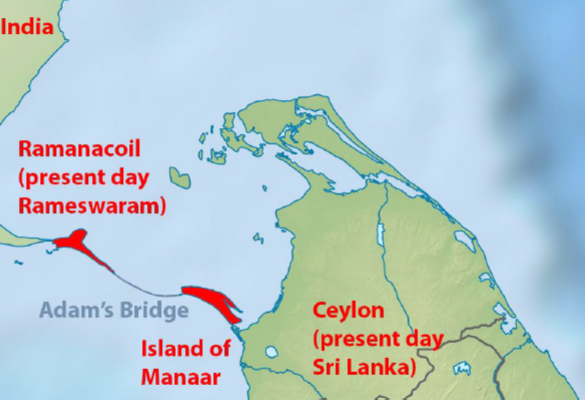
Ramanacoil, Island of Manaa, and Ceylon
The island of Ramanacoil, known today as Rameswaram, is situated off the mainland of South India. It is historically significant due to its connection with the Island of Manaar through Adam’s Bridge, a natural chain of limestone shoals. This geographical feature has been of interest for its historical and cultural connections, forming a link between India and Sri Lanka.
In 1674, during the Franco-Dutch War (1672-1678), Rijckloff Van Goens had ambitious expansion plans for the Dutch East India Company (VOC) in Asia. He made up a ‘wish list’ of territories he wanted to conquer. These ambitions took place against the backdrop of the war in which the Netherlands and the VOC were fighting against France, England and several other countries.
The Journey of an Encrypted Letter
In a time when communication was fraught with risks of interception and misinterpretation, an encrypted letter on this topic (conquering new land) from Rijckloff Van Goens embarked on a remarkable journey spanning approximately 10,000 kilometers. Dispatched from Ceylon, a crucial VOC stronghold of the time, the letter was carried by Van Goens private secretary Leeuwenson. Accompanied only by a single soldier for protection, Leeuwenson carried both the letter and additional memorized information for the Lord Seventeen. The journey took them 243 days. Van Goens, wary of the ongoing war against England and Spain, chose this over the sea route to ensure the message’s safety. To avoid detection, Leeuwenson and his companion disguised themselves in oriental clothing, blending in during their arduous and secretive journey (see first image of this blog article to get an idea how they may have looked like).
Leeuwenson presents the letter to the Lords Seventeen (AI-generated)
In the letter carried by Leeuwenson, Van Goens outlined significant military ambitions. He demanded the conquest of all Sri Lanka, Ramanacoil Island, and surrounding Indian coastal areas. To achieve this, he requested an additional 1,000 soldiers, planning to employ the successful tactics he used in 1655. Leeuwenson not only delivered this encrypted letter to the Lords Seventeen but also relayed additional memorized information. However, despite Van Goens’ efforts and strategic vision, the Lords Seventeen rejected his proposal. The VOC had shifted its expansionist strategy to a more cost-effective approach, focusing on reducing the number of locations and soldiers.
The Letter and Its Decipherment
Example of the “Ramanacoil Transcript”
Today, the intriguing letter sent by Van Goens is preserved in the National Archives in The Hague. This historical document, spanning 46 pages, is mostly encrypted using alchemical and astrological symbols. Fascinatingly, a copy of the key to this cipher is stored alongside the letter.
The original key of the “Ramanacoil Transcript” found besides the original letter
Students from the University of Uppsala transcribed the encrypted document, and my colleague Jörgen Dinnissen and I conducted a thorough cipher analysis, leading to publications in HistoCrypt [1] and the German computer magazine c’t [2]. We incorporated the key into CrypTool 2, facilitating an easy decryption of the letter, despite the transcription process being more time-consuming. The cipher, a monoalphabetic substitution cipher, omits the letters V and J and includes symbols for five double letters. Intriguingly, the words ‘CEYLON’ and ‘RAMANACOIL’ appear in the plaintext without corresponding nomenclature elements, hinting that Leeuwenson might not have crafted the key. Jörgen’s deeper analysis of the cipher elements offers further insights into this historical cryptographic puzzle.
References
You may read the English research article as well as the German article in the c’t. Also, here is a link to the cipher in the DECODE database.
[1] Dinnissen, J. & Kopal, N. Island Ramanacoil a Bridge too Far. A Dutch Ciphertext from 1674. In Proceedings of the 2021 International Conference on Historical Cryptology (HistoCrypt 2021) (pp. 48 57). 2021. url: https://ecp.ep.liu.se/index.php/histocrypt/article/view/156
A few weeks ago, I was asked by a viewer of my YouTube channel (“Cryptography for everybody”) if there was an “affine cipher component” in CrypTool 2. After taking a look at all our components, I realized that there was no component that implemented this cipher. I made a video for new CrypTool 2 developers and how they may implement the affine cipher, as an example of how to build new CrypTool 2 components. But I never added such an affine cipher component to CrypTool 2. So I sat down and created a brand new component and also made a YouTube video about the cipher (see the video at the end of this blog article). Also, in this blog article I summarize the video and how the encryption process works. You’ll also learn about the size of the key space and the unicity distance of the affine cipher. I hope you enjoy reading the article and that you understand how the cipher works afterwards.
1. Introduction to the Affine Cipher
The affine cipher is essentially a monoalphabetic substitution cipher, which means each letter of the plaintext is substituted with another letter to form the ciphertext. This method can trace its origins back to the time of the Caesar cipher, a cipher used in ancient Rome.
Over the course of history, as the mathematical domain grew, so did the complexity and strength of ciphers. The affine cipher is a one of the first testaments to this growth, combining the principles of two basic ciphers: the additive and the multiplicative cipher.
An interesting aspect of the affine cipher, and the ciphers we’ll be discussing, is that they operate on numbers. The ciphers essentially translate each letter of the used alphabet (e.g. the Latin alphabet) into a number (and back), providing a platform for mathematical operations. This translation is quite straightforward:
2. The Additive Cipher
Let’s start with the basics. The additive cipher functions by adding an offset number to each letter, shifting it to the right. This is the underlying principle behind the famous Caesar cipher.
The multiplicative cipher involves multiplying each letter with a specific number. This process essentially “randomly selects” a letter from the alphabet, but still for each plaintext letter always the same ciphertext letter.
Key elements:
Key: The multiplication value, denoted as 𝒂. However, there needs to be an inverse (𝑎⁻¹) of this value for decryption. For a number 𝒂 to have a multiplicative inverse modulo m (here the alphabet size, which is 26), 𝒂 and m must be coprime, which means their greatest common divisor (GCD) is 1. In mathematical terms: gcd(a,m)=1.
Encryption: 𝑐 = (𝑝 ∙ 𝑎) 𝑚𝑜𝑑 26
Decryption: 𝑝 = (𝑐 ∙ 𝑎⁻¹) 𝑚𝑜𝑑 26
To illustrate, let’s use 𝑎 = 5 (with its inverse 𝑎⁻¹ = 21):
Note: Computing the inverse of a number in modular arithmetic is crucial. Techniques like the extended Euclidean algorithm (see https://en.wikipedia.org/wiki/Extended_Euclidean_algorithm) come in handy, and we’ll delve into this in a future discussion (and youtube video :-))!
4. The Affine Cipher
Building on the previous concepts, the affine cipher is a combination of both additive and multiplicative ciphers.
Key components:
Key: Comprises a multiplication value 𝒂 and a shift value 𝒃.
Encryption: 𝑐 = (𝑝 ∙ 𝑎 + 𝑏) 𝑚𝑜𝑑 26
Decryption: 𝑝 = (𝑐 − 𝑏) ∙ 𝑎⁻¹ 𝑚𝑜𝑑 26
For a hands-on example, using 𝑎 = 5 (inverse 𝑎⁻¹ = 21) and 𝑏 = 5:
Understanding key spaces and unicity distances is essential for appreciating the security of a cipher:
Keyspace size: For the affine cipher, we have 25 possible values for 𝒂 and 26 for 𝒃. However, 𝒂 and 26 need to be coprime. Thus, only specific values are valid for 𝑎 as they possess an inverse (𝑎⁻¹). These values are 1, 3, 5, 7, 9, 11, 15, 17, 19, 21, 23, and 25. The total key space is then 12 x 26 = 312.
Unicity distance (𝑈): This concept helps determine the number of characters required to uniquely identify plaintext from its ciphertext. For the affine cipher, using the entropy of the key space (𝐻(𝐾)) and the redundancy of the English language (𝐷), the unicity distance is approximately 3. The equation to compute the unicity distance is U = H(K)/D.
In essence, the affine cipher, with its mathematical underpinnings and historical significance, offers an exciting glimpse into the world of cryptography. Whether you’re a beginner or an aficionado, diving into these ciphers can be both intriguing and rewarding. Stay tuned for more cryptographic adventures also with CrypTool 2
6. A YouTube Video About the Affine Cipher
Of course, I also made a YouTube video about the affine cipher. You may watch it here:
The Affine Cipher – A Mathematical Substitution Cipher
Some days ago, I saw a very interesting hand cipher called the “Grandpré cipher”. It is not interesting because it was very secure or original. It is interesting because the “keying process”, i.e. the search for words for usage as the key(s), was kind of tedious. In this blog article, I will explain the background of the cipher, how it works, and its keyspace size and unicity distance.
History of the Grandpré Cipher
The cipher is said to be first published by A. de Grandpré in his 1905 French book “Cryptographie pratique”. It was later named after the author. Unfortunately, I did not find any information on the author despite his (or her?) last name. So, I actually don’t know what the “A.” stands for. The description of the cipher itself can be found in the book on page 31. The chapter is named “Méthode de carre de 10×10”, which can be translated to “10×10 square method”. Grandpré defined the method for squares of 10×10, but squares with smaller sizes (9, 8, 7, 6) can also be used. We did also implement the cipher in a CrypTool 2 component. So if you want to try it by yourself, you may download CrypTool 2 to do so. Here, we show the original cover of Grandpré’s book:
The Grandpr´é cipher is a homophonic substitution cipher based on a keyword and several additional words. The cipher encrypts plaintext letters into two-digit ciphertext numbers. It uses a table to do so. We will discuss how this works in the next section.
Table Creation Based on Keyword and Words
First, we need to find 10 words (or less), depending on our selected table size. The table size depends on our chosen secret keyword. Let’s say our secret keyword is “VIMOUTIERS” as used by Grandpré in his book. This keyword has 10 letters, so our table has to be a 10×10-sized table.
Now, we have to find 10 more words, each starting with a letter of our secret keyword. So a word for “V”, let’s take “VOLUPTUEUX”, a word for “I”, let’s take “INQUIETUDE”, and so on. Of course, here, for the example, we used the same words which Grandpré used in his book. To create the table, we write the keyword in the first column and the additional words in the rows. Each word starts with one of the letters of the keyword. The final table looks like the one below. But besides adding only the words, we also add digit coordinates (from 1 to “keyword length”; 10 = 0) to the rows and columns:
10×10-table based on the keyword “VIMOUTIERS” as shown by Grandpré in his book
Encryption and Decryption
Now, we can use this table to encrypt a text. To encrypt a letter, we need to find it in the table. Then, we use the row R and column C to create our ciphertext symbol “RC”. Examples: E = “34”, A = “47”, E = “66”. Here, you can also see why the cipher is a homophonic substitution cipher. We have several options to choose from for most of the letters. But you can also see the drawback of the cipher. It is troublesome to find words for the table creation that contain all letters of our alphabet. Especially rarely used letters like Q and X are difficult to add to the table.
As an example, here is the encryption of the plaintext “HELLO WORLD”:
As you can see, we have several valid ciphertexts. Since the Grandpré cipher is a homophonic substitution cipher, we can use different homophones to create a variety of valid ciphertexts.
Clearly, the decryption of a given ciphertext is the inverse process. Here, you always take two digits and lookup the corresponding plaintext letter in the same table as used for encryption.
Keyspace Size and Unicity Distance
Here, we calculate the size of the keyspace and the unicity distance of the Grandpré cipher. We compute the largest possible keyspace obtained by using a 10×10 table.
For the 10 x 10 case, there are 10 ∙ 10 = 100 cells in the table. Thus, we have a total number of 26^100 = 2^470 tables. But we use English words and don’t use the complete “table space”. Thus, let’s consider English has about 2,000 10-letter words. Then, we would “only” have 2000^10 valide tables, which is about 2^110 different tables.
Now, based on the above computed keyspace, lets compute the unicitiy distance U. It is the minimum number of letters needed when cryptanalyzing a ciphertext which allows us to be able to obtain only one valid solution. Below this number, we can find multiple valid English texts. To compute the distance, we have to divide the entropy of the keyspace H(K) by the redundancy D of the English language:
We need a minimum of 35 letters to be able to obtain only a single valid solution through cryptanalysis. Clearly, a given ciphertext can be solved like any other digit-based homophonic substitution cipher :-).
A YouTube Video About the Cipher
I also made a YouTube video about the Grandpré cipher. You can watch it here 🙂
Recently I stumbled across a very interesting cipher named ElsieFour (LC4), see specification in [1]. This cipher is a low tech cipher that can be computed by hand. It was developed by Alan Kaminsky and published in 2017. According to Kaminsky, it is designed hard to break. It is an amalgam of ideas from the RC4 stream cipher, the Playfair cipher, and the notion of plaintext dependent keystreams. It is a polyalphabetic substitution cipher. Besides encryption by hand, LC4 also allows authentication by hand. But this is not part of this blog article :-).
How does it work?
ElsieFour operates on a 36-letter plaintext alphabet A-Z, 0-9 (where 0 is # and 1 is _). The key is a permutation of this alphabet. LC4 uses a 6×6 grid filled with the keyed alphabet.
Encryption works as follows: 1. Choose a key (a particular permutation of the 36-character alphabet) and arrange it in a 6×6 grid 2. For each character in the plaintext message: a) Determine the position of the character in the grid b) Apply a sequence of movements in the grid (this includes moving the character, moving a “marker”, and possibly going around the edges of the grid) to determine the position of the ciphertext character c) Write down the character at the new position as the next character in the ciphertext d) Permute the grid in a specific way
Key Generation
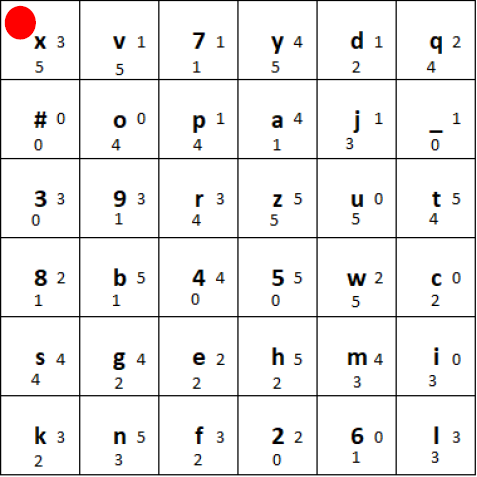
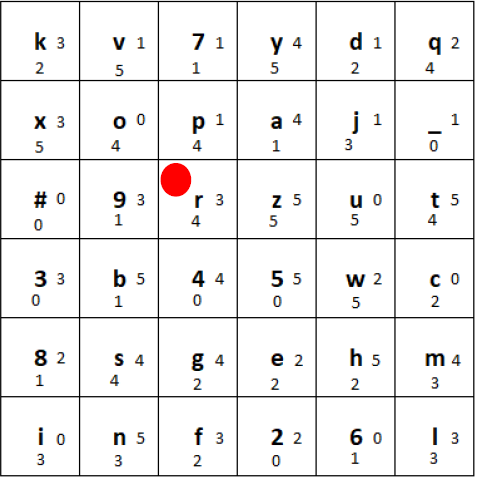
Choose a key (a particular permutation of the 36-character alphabet) and arrange it in a 6×6 grid (e.g. “xv7ydq#opaj_39rzut8b45wcsgehmiknf26l”). And put the marker (red circle) into the top left corner. The tiles used for the grid are wooden plates which have the character and two small digits written on them:
Initial state of the grid generated using the key
Encryption
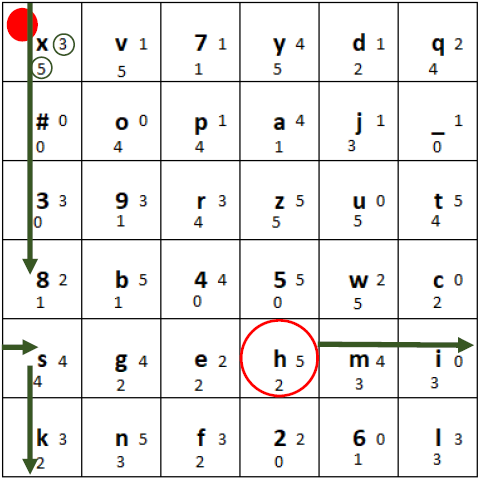
Here, we encrypt for example the plaintext “hello world”. For each character in the plaintext message:
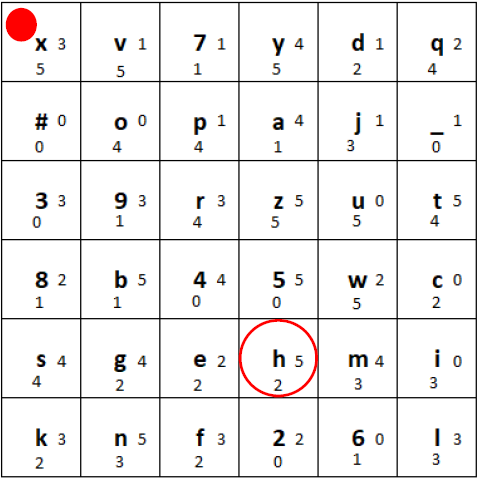
1) We determine the position of the character (here the letter “h”) in the grid:
Marked position of the letter “h”
2) Then, we use the two small digits right and to the bottom of the marked letter. In this case the 3 and the 5. Go from the plaintext letter 3 to the right (wrapping around) and 5 to the bottom (wrapping around):
Determining the “movement” of the plaintext letter to obtain the ciphertext letter
3) After that, we write down the ciphertext letter (in this case the digit “8”).
4) Now, we permute the grid in the following way:
a) First, in the row with the plaintext character, we shift the tiles one position to the right, and put the rightmost tile at the beginning of the row:
Plaintext row shifted one position to the right
b) Secondly, in the column with the ciphertext character, we shift the tiles one position down, and put the bottommost tile at the beginning of the column. If the marker’s tile moves, the marker stays on that tile:
Ciphertext column shifted one position to the bottom.
c) Finally, we move the marker to the right the number of tiles shown at the right side of the ciphertext tile (here 2), wrapping around to the beginning of the row if necessary. We move the marker down the number of tiles shown at the bottom of the ciphertext tile (here 1), wrapping around to the beginning of the column if necessary.
Moving of the marker
The final state of the grid after encrypting the first letter should look like this:
Final state after encrypting the first letter “h” and moving the tiles according to the rules
If we encrypt the plaintext “hello world” using the above shown procedure with every plaintext letter, the final ciphertext is “8#4l_3lcf8s”.
The decryption is the inverse process. We implemented the ElsieFour cipher in CrypTool 2, thus, if you want to use it without the need of creating wooden tiles, you can download CrypTool 2 and use the ElsieFour component :-). Go to https://www.cryptool.org/en/ct2/downloads
Keyspace size and unicity distance
The keyspace size k is the number of all possible permutations of the 36 letter alphabet:
The unicity distance U is (entropy of keyspace H(k) divided by redundancy D of the language):
One final remark: If you make only one single mistake when encrypting or decrypting, the following plaintext or ciphertext is broken 🙁
A YouTube video about ElsieFour
I also made a YouTube video about the ElsieFour cipher :-). You can watch it here:
ElsieFour (LC4) – A Low-Tech Cipher Inspired by RC4
References
[1] Kaminsky, Alan. “ElsieFour: A Low-Tech Authenticated Encryption Algorithm For Human-To-Human Communication.” Cryptology ePrint Archive (2017). url: https://eprint.iacr.org/2017/339.pdf
The Typex is a cipher machine used by the British during World War II. It is, similar to the German Enigma cipher machine, an elector-mechanical rotor encryption machine. In contrast to the Enigma, the Typex was not broken during WWII. The Germans believed that Enigma is unbreakable and since Typex is very similar, they did not even attempt to break the machine.
I recently wrote a new CrypTool 2 component that implements the Typex cipher machine. If you are interested in testing the component (and the machine) yourself, you should download the latest nightly build of CrypTool 2.
History and Usage of the Typex
The Typex machine was used for a) Encryption of the own communication b) Deciphering German Enigma messages
It was developed by Wing Commander Oswyn G.W. Lywood, Flight Lieutenant Coulson, Mr. E. W. Smith, and Sergeant Albert Lemon.
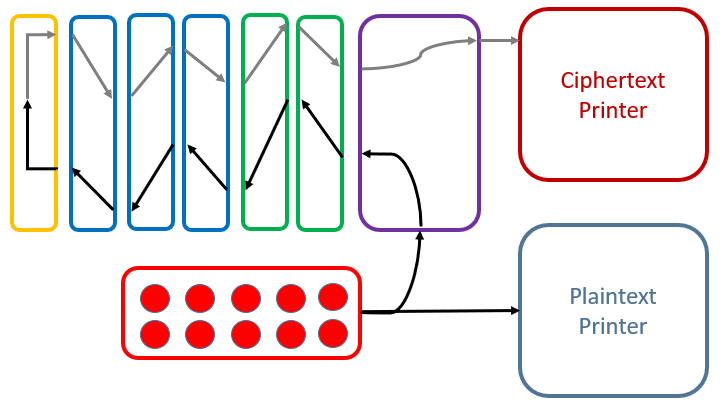
In the following, we have a look at the machine’s components. The Typex machine consists of:
Components of Typex
Typex machine with marked components
Logical overview of Typex components
When pressing a key on the keyboard, the plaintext letter is printed by the plaintext printer. Also, current flows through the plugboard, the two stators, the three rotors and is then reflected by the reflector. Then it flows back through the three rotors and the two stators as well as the plugboard. Finally, the ciphertext letter is printed by the ciphertext printer.
Clearly, every time a key is pressed, between one and all three rotors move (Stators of course don’t move). In contrast to Enigma, a Typex rotor moves much more often. This is because the rotors have between 4 and 7 notches, while Enigma rotors had at most two notches.
The Typex Plugboard
The Typex plugboard is the first (and last) component (despite the printers), which current is lead through after a key is pressed on the keyboard. It allows to “plug” letters, creating an initial monoalphabetic substitution.
Typex plugboard
The plugboard is not reciprocal (like the Enigma‘s plugboard. With Enigma, if we have letter X to letter Y, then we would also have letter Y to letter X). It, thus, offers a larger keyspace than Enigma’s plugboard.
The Typex Rotors/Stators
Typex consists of two stators and three rotors. A rotor has more „notches“ than Enigma rotors (in CrypTool 2’s Typex implementation between 4 and 7). A rotor’s electrical contacts are doubled to improve reliability. Unfortunately, the original rotors are not published and still kept secret, thus, the simulators use no official rotor definitions.
Typex rotor
The Typex Reflector
The Typex reflector “reflects” the current coming from the rotors back through the rotors. In later Typex versions the reflector was replaced by an additional plugboard which allowed to change the reflector’s wiring easily.
Typex reflector
Keyspace Size and Unicity Distance
Since no original rotor definitions are known, the computation of keyspace size and unicity distance is based on the “CyberChef” Typex simulator written and published by GCHQ (see https://gchq.github.io/CyberChef/).
With this implementation, we have to choose 5 rotors (3 actual rotors and 2 stators) from a set of 8 rotors. Since a rotor can be put into the machine in forward or reversed position, they basically doubled the amount of usable rotors to 16. Here, we assume that we can use each rotor as many times as we like in parallel. Thus, the “rotor keyspace size” is:
Typex rotor keyspace size (“CyberChef” version)
We have to set the rotor start positions. We have five rotors (3 actual rotors and 2 stators). Each rotor can be in one of 26 different positions (A-Z). Thus, we have a total “start position keyspace” of:
Typex start position keyspace size
The plugboard is basically a simple monoalphabetic substitution cipher. That means, for the first letter we have 26 different letters to choose from, for the second letter, we have 25 different remaining letters to choose from,… Thus, the “plugboard keyspace” is:
Typex plugboard keyspace size
To compute the overall keyspace size, we have to multiply all “sub-keyspace” sizes:
Total keyspace size of the Typex (“CyberChef” version)
To compute the unicity distance U, we have to divide the entropy of the keyspace by the redundancy of the (English) language:
Typex unicity distance U (“CyberChef” version)
This means, we need a minimum of 42 letters to be able to obtain a single valid solution when we perform cryptanalysis of a Typex message.
A YouTube Video about Typex and a Web-Based Simulator
I also created a YouTube video about the Typex cipher machine. Here, I discuss the machine as well as its keyspace size and unicity distance. Also, I show how to use the Typex component in CrypTool 2:
The British Typex Cipher Machine Explained
Finally, if you want to “play” with a really nice simulator (and also want to learn much more about the Typex), you should have a look at the “Virtual Typex”: https://typex.virtualcolossus.co.uk/Typex/
The usage of the simulator is also shown in the above linked YouTube video :-).
Screenshot of the “Virtual Typex”
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept All”, you consent to the use of ALL the cookies. However, you may visit "Cookie Settings" to provide a controlled consent.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.