Some days ago, I saw a very interesting hand cipher called the “Grandpré cipher”. It is not interesting because it was very secure or original. It is interesting because the “keying process”, i.e. the search for words for usage as the key(s), was kind of tedious. In this blog article, I will explain the background of the cipher, how it works, and its keyspace size and unicity distance.
History of the Grandpré Cipher
The cipher is said to be first published by A. de Grandpré in his 1905 French book “Cryptographie pratique”. It was later named after the author. Unfortunately, I did not find any information on the author despite his (or her?) last name. So, I actually don’t know what the “A.” stands for. The description of the cipher itself can be found in the book on page 31. The chapter is named “Méthode de carre de 10×10”, which can be translated to “10×10 square method”. Grandpré defined the method for squares of 10×10, but squares with smaller sizes (9, 8, 7, 6) can also be used. We did also implement the cipher in a CrypTool 2 component. So if you want to try it by yourself, you may download CrypTool 2 to do so. Here, we show the original cover of Grandpré’s book:

Cryptographie pratique (1905) by A. de Grandpré
The American Cryptogram Association (ACA) has added the Grandpré cipher to its portfolio of “standard ciphers”. Their description of the cipher can be found here: https://www.cryptogram.org/downloads/aca.info/ciphers/Grandpre.pdf
The Grandpr´é cipher is a homophonic substitution cipher based on a keyword and several additional words. The cipher encrypts plaintext letters into two-digit ciphertext numbers. It uses a table to do so. We will discuss how this works in the next section.
Table Creation Based on Keyword and Words
First, we need to find 10 words (or less), depending on our selected table size. The table size depends on our chosen secret keyword. Let’s say our secret keyword is “VIMOUTIERS” as used by Grandpré in his book. This keyword has 10 letters, so our table has to be a 10×10-sized table.
Now, we have to find 10 more words, each starting with a letter of our secret keyword. So a word for “V”, let’s take “VOLUPTUEUX”, a word for “I”, let’s take “INQUIETUDE”, and so on. Of course, here, for the example, we used the same words which Grandpré used in his book. To create the table, we write the keyword in the first column and the additional words in the rows. Each word starts with one of the letters of the keyword. The final table looks like the one below. But besides adding only the words, we also add digit coordinates (from 1 to “keyword length”; 10 = 0) to the rows and columns:

10×10-table based on the keyword “VIMOUTIERS” as shown by Grandpré in his book
Encryption and Decryption
Now, we can use this table to encrypt a text. To encrypt a letter, we need to find it in the table. Then, we use the row R and column C to create our ciphertext symbol “RC”. Examples: E = “34”, A = “47”, E = “66”. Here, you can also see why the cipher is a homophonic substitution cipher. We have several options to choose from for most of the letters. But you can also see the drawback of the cipher. It is troublesome to find words for the table creation that contain all letters of our alphabet. Especially rarely used letters like Q and X are difficult to add to the table.
As an example, here is the encryption of the plaintext “HELLO WORLD”:

As you can see, we have several valid ciphertexts. Since the Grandpré cipher is a homophonic substitution cipher, we can use different homophones to create a variety of valid ciphertexts.
Clearly, the decryption of a given ciphertext is the inverse process. Here, you always take two digits and lookup the corresponding plaintext letter in the same table as used for encryption.
Keyspace Size and Unicity Distance
Here, we calculate the size of the keyspace and the unicity distance of the Grandpré cipher. We compute the largest possible keyspace obtained by using a 10×10 table.
For the 10 x 10 case, there are 10 ∙ 10 = 100 cells in the table. Thus, we have a total number of 26^100 = 2^470 tables. But we use English words and don’t use the complete “table space”. Thus, let’s consider English has about 2,000 10-letter words. Then, we would “only” have 2000^10 valide tables, which is about 2^110 different tables.
Now, based on the above computed keyspace, lets compute the unicitiy distance U. It is the minimum number of letters needed when cryptanalyzing a ciphertext which allows us to be able to obtain only one valid solution. Below this number, we can find multiple valid English texts. To compute the distance, we have to divide the entropy of the keyspace H(K) by the redundancy D of the English language:
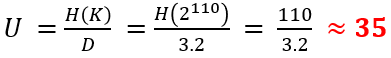
We need a minimum of 35 letters to be able to obtain only a single valid solution through cryptanalysis. Clearly, a given ciphertext can be solved like any other digit-based homophonic substitution cipher :-).
A YouTube Video About the Cipher
I also made a YouTube video about the Grandpré cipher. You can watch it here 🙂
